
Artificial Intelligence vs Machine Learning Explained for Beginners
Short summary :
If you have ever tried to read about artificial intelligence basics, you quickly hit a wall of jargon. I get it. I have sat through long slide decks and still felt fuzzy about the difference between AI and machine learning. This post is for students, non-technical professionals, startup founders, marketers, and anyone who wants a clear, usable explanation without the fluff.
We will walk through the core ideas, show simple examples, and cover the practical stuff you actually need to know. I will point out common mistakes I see in the wild and give quick tips you can use when evaluating tools or starting a project. Think of this as a friendly cheat sheet for AI technology explained in plain language.
Quick definitions to get started
Let us begin with short, clear definitions. Keep these in your back pocket.
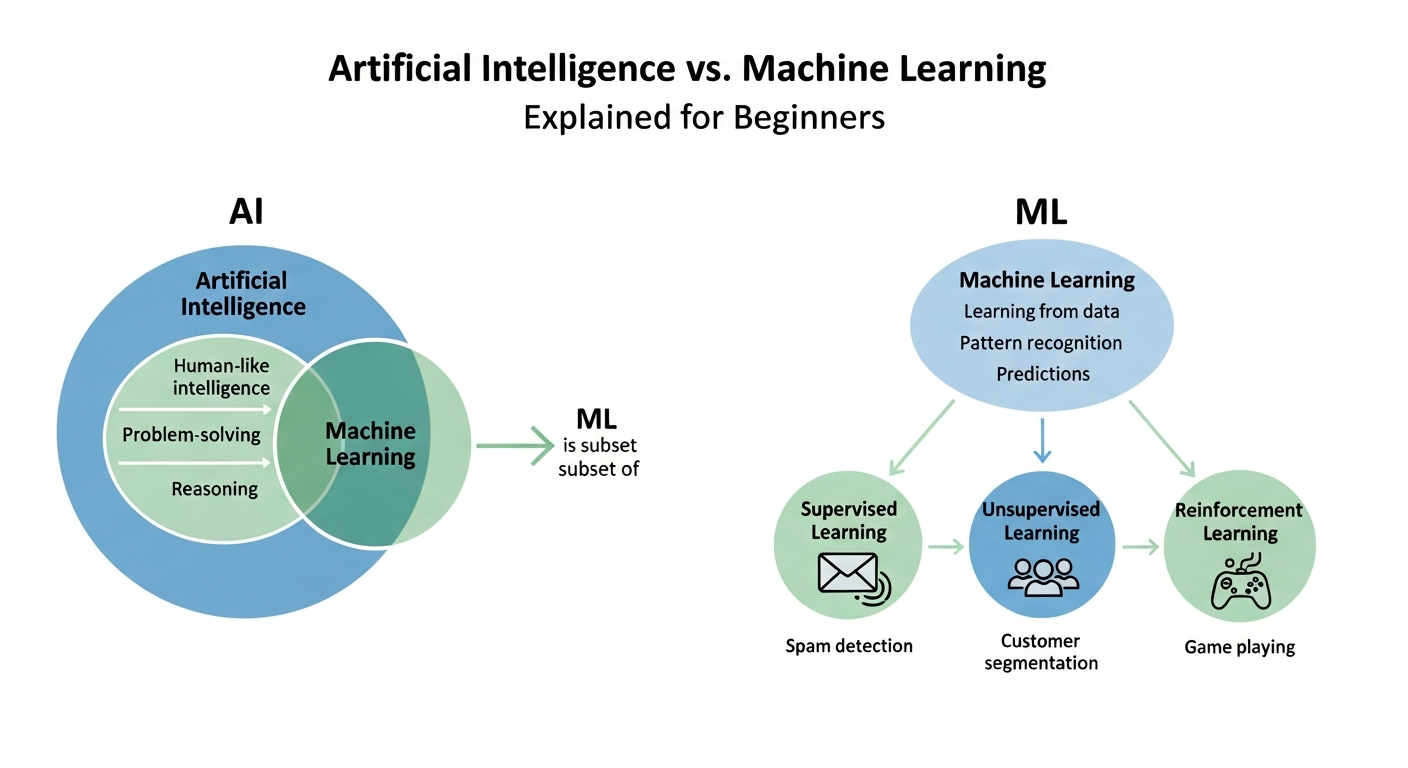
- Artificial intelligence means any system that performs tasks we normally associate with human thinking. That could be recognizing voice, planning routes, or recommending a movie. It's a broad field that aims to create systems that act intelligently.
- Machine learning is a way to build AI. Instead of programming every rule, we give the system data and let it learn patterns. Machine learning models find connections between inputs and outputs.
In short, machine learning is a subset of artificial intelligence. AI is the big umbrella. ML sits under it.
Why the confusion? A quick analogy
Here is a simple metaphor I like. Think of artificial intelligence as the entire kitchen. Machine learning is one of the cooking appliances. You can use an oven to make food. But you could also use a stove, microwave, or toaster. They all create meals, but they work differently.
People often say AI when they really mean machine learning. That is okay, but it matters when you decide what technology to use for a business problem.
Types of artificial intelligence
AI can be described in a few common ways. These categories help us talk about goals and limits.
- Narrow AI does one thing well. Voice assistants, recommendation engines, and spam filters are narrow AI. Most AI today is narrow.
- General AI would match human cognitive ability across a wide range of tasks. We do not have it yet. It is the stuff of sci fi and long term research.
- Reactive vs. adaptive systems is another split. Reactive systems respond to current inputs only. Adaptive systems change based on experience. For example, a chess engine that learns from games is adaptive.
When you read news stories about AI breakthroughs, they usually describe improvements in narrow AI. That is where progress is fastest and most commercially useful.
Types of machine learning
Machine learning basics break down into a few practical approaches. Each one is useful for different tasks.
- Supervised learning uses labeled examples. If you want to teach a model email categories, you give it emails labeled as "spam" or "not spam."
- Unsupervised learning finds structure in unlabeled data. Clustering customer types is a typical use. You do not tell the model what the groups are.
- Semi supervised learning mixes a small amount of labeled data with a lot of unlabeled data. It is a practical middle ground when labeling is expensive.
- Reinforcement learning teaches an agent by trial and error. It works well for control problems like game playing and robotics.
- Self supervised learning recently became popular. The model creates its own labels from the data to learn useful representations. Big language models use this trick.
In my experience, supervised learning is the easiest place to start if you have labeled data. For many business problems, simple supervised models outperform fancy methods because they are easier to evaluate and maintain.
How machine learning actually works — step by step
People imagine machine learning as magic. It is not. It is a repeatable process. Here is a simple, practical pipeline you can follow.
- Define the problem. What do you want the model to do? Classify, predict a number, or cluster items? The question shapes everything else.
- Collect data. More data is usually better, but the right data matters more than volume. Are the fields you need being captured reliably?
- Prepare data. Clean missing values. Normalize numbers. Convert text into tokens. Real projects spend most time here.
- Select a model. Start simple. Logistic regression, decision trees, and random forests are great baselines. Then try more complex models if needed.
- Train the model. Fit the model to the training data. Monitor training time and resource use.
- Evaluate. Hold out a test set or use cross validation. Look at metrics that matter to your business, not just accuracy.
- Deploy. Put the model into production. Monitor performance and set up retraining when the data shifts.
- Iterate. Models degrade over time. Keep measuring and improving.
Anyone who has trained models knows one thing: step three eats time. Data preparation is where projects stall. Plan for it.
Common machine learning examples that make sense
Let us keep the examples simple. These are the kinds of projects you will actually see in companies.
- Spam detection. A classic supervised learning task. Label emails as spam or not. Train a text classifier.
- Recommendation systems. Suggest products or content based on past behavior. Collaborative filtering and hybrid models are common here.
- Customer churn prediction. Predict which customers might leave. Use features like usage, frequency, and support tickets.
- Image tagging. Identify objects in photos. Convolutional neural networks are common. You can start with pre trained models.
- Sentiment analysis. Classify text as positive or negative. Useful for social listening and customer feedback.
These examples show how machine learning solves measurable business problems. If your goal is to improve a metric, ML can often help. But only when you ground the question properly first.
AI vs ML difference: practical signals to look for
How do you tell whether a project needs AI in general or machine learning specifically? Here are some practical signs.
- If your task needs rules and logic without learning, you might not need ML. Example: applying a fixed discount for orders over a threshold.
- If patterns change and are too complex to hand code, machine learning makes sense. Think dynamic pricing or ad targeting.
- If you need predictions or classifications from messy data like images, text, or sensor signals, ML is the usual choice.
- If you need planning, reasoning, or symbolic manipulation, you might explore other AI techniques beyond ML.
In short, ML is your go-to when you have data that encodes the answer implicitly. If you can write clear rules that never change, stick with rules. They are cheaper and more reliable.
Data matters. Seriously.
Good models start with good data. I have seen teams try to force a fancy model on tiny or biased datasets. That rarely ends well.
Here are a few practical checks I use before modeling:
- Is the dataset representative of the situations where the model will run? If not, you will see unexpected failures.
- Are labels clean? Noisy labels break supervised learning. If labeling is inconsistent, consider a review process.
- Do you have enough examples of important classes? Imbalanced classes are a common trap. Techniques like resampling help, but the best fix is more data.
- Is the data fresh? Models trained on stale data can underperform quickly when behavior changes.
Spend time exploring the data. Plot distributions. Look at edge cases. Talk to domain experts. These steps save engineering hours later.
Common mistakes and pitfalls
Let me call out a few mistakes I see over and over. Avoiding them will save time and embarrassment.
- Confusing correlation with causation. Models find patterns, not reasons. A model might associate ice cream sales with drownings because both rise in summer. Do not confuse that with a causal relationship.
- Using accuracy as the only metric. If your classes are imbalanced, accuracy lies. Use precision, recall, AUC, or business KPIs instead.
- Overfitting. A model that performs perfectly on training data often fails in production. Regularize, validate properly, and keep models simple when possible.
- Ignoring data leakage. This happens when information from the future sneaks into the training data. It leads to unrealistically good results during testing and poor results in real life.
- Neglecting monitoring. Models drift. Data patterns change. Set up alerts and periodic reevaluation.
I once saw a model that looked amazing in development but fell apart in production because the date column leaked future holiday discounts into the features. The team had to rebuild with proper care. It is an easy mistake to make.

Explainability, fairness, and ethics — the practical bits
These topics are not just academic. They affect adoption and compliance. People want to know why a model made a decision. Regulators increasingly require explanations.
Here are concrete, practical steps you can take:
- Start with simple models when possible. They are easier to explain.
- Use model interpretation tools like SHAP or LIME to explain feature importance for complex models.
- Check for bias in training data. Does the model systematically underperform for a subgroup? If so, fix the data or adjust the objective.
- Document assumptions and limitations. A short note can prevent misuse.
Sometimes a transparent model that is 2 to 5 percent worse in performance is a better choice than a black box. Trust matters.
Tools and platforms — where to start
If you want to try machine learning basics, you do not need to build everything from scratch. Plenty of tools let you get hands on fast.
- For experimentation: Python with scikit learn, pandas, and matplotlib is a solid starting stack.
- For deep learning: PyTorch or TensorFlow. PyTorch feels friendlier for beginners.
- For text and large models: Hugging Face provides models and datasets you can use right away.
- For quick prototypes: AutoML platforms and low code tools can get you to a proof of concept quickly. They are not magic, but they speed up iteration.
- For production: Managed platforms like AWS SageMaker, Google AI Platform, or MLOps tools help deploy and monitor models reliably.
My rule of thumb is to prototype with simple tools. If you need scaling later, move to production-grade platforms. Keep the prototype reproducible so you can migrate cleanly.
How to evaluate a model the right way
Evaluation is where many teams fail. It is tempting to chase a single number. Instead, match evaluation to how the model will be used.
Some practical tips:
- Hold out a realistic test set that matches production. If your production traffic is seasonal, your test set should reflect that.
- Measure the metrics that map to business value. Will better precision reduce costs? Will better recall improve revenue?
- Run A B tests in production when possible. Simulation is helpful, but real user feedback is the final judge.
- Track false positives and false negatives separately. Their business costs are rarely equal.
When I help teams evaluate models, I focus first on what errors cost the company. That keeps work grounded.
When AI or ML is not the right solution
AI is a powerful set of tools. However, it is not always the right answer. Consider these cases:
- If a business rule solves the problem reliably, do not add ML complexity. A rule is predictable and easy to audit.
- If you lack data and can't collect it, ML will struggle. In those cases, instrument your product first to gather the right signals.
- If the cost of mistakes is high and you cannot explain decisions, think twice. You may need human oversight or simpler models.
Every founder I know wants to sprinkle AI on their product. My advice? Be strategic. Use AI SEO and other AI capabilities where they change a metric meaningfully.
Practical roadmap for beginners and teams
If you are starting from scratch, here is a simple roadmap I recommend. It keeps risk low and learning fast.
- Pick a clear business question. Keep it focused. "Reduce churn by 10 percent" beats "use AI."
- Gather and explore data. Spend time understanding distributions and edge cases.
- Build a benchmark. Baseline with simple heuristics or rules. Make sure any model beats that baseline.
- Prototype quickly. Use off the shelf models or AutoML for a first pass.
- Validate rigorously. Use held out tests and, when possible, an A B test.
- Deploy with monitoring. Track model performance, latency, and business metrics.
- Iterate. Fix data issues, retrain, and improve the feature set based on real-world feedback.
This sequence reduces wasted effort and helps you focus on measurable wins.
What Is an E-Learning Platform & How It Works | Vidyanova
Tips for marketers and product people
You do not need to be a data scientist to benefit from AI. Here are practical things marketers and product managers can do right away.
- Start small with personalization. Even simple recommendation rules improve engagement.
- Use out of the box analytics for segmentation before trying clustering models.
- Define the success metric clearly. Conversion lift, retention, and lifetime value are common choices.
- Partner with engineers to instrument key events. Without good telemetry, models are guessing.
- Keep users in the loop. Transparent personalization improves trust and click through rates.
One quick experiment I recommend: run a simple personalization A B test using past behavior. It is cheap and tells you if more advanced ML is worth the investment.
Simple examples you can try today
Want to get your hands dirty? Here are three approachable projects. Each teaches core concepts without overwhelming you.
- Spam classifier. Use a dataset of labeled emails. Try a bag of words model with logistic regression. It teaches text preprocessing and evaluation.
- Customer churn predictor. Use historical user activity and subscription information. A decision tree gives interpretable results quickly.
- Product recommender. Start with simple collaborative filtering or rule based recommendations. Measure uplift and iterate.
None of these need heavy infrastructure. I have built all three in a weekend for demos. The lessons you learn are directly applicable to larger systems.
Resources to learn more
If you want structured learning, these resources are practical and beginner friendly.
- Online courses: Coursera and edX have introductory courses that cover machine learning basics.
- Books: "Hands On Machine Learning with Scikit Learn, Keras and TensorFlow" is a good practical guide.
- Blogs and communities: Follow practical blogs and join forums to see real problems and solutions.
- Open datasets: Kaggle is great for practice datasets and community notebooks.
Learning by doing trumps theoretical reading for most business applications. Try small projects and learn from the mistakes. That is how skills stick.
Common questions I get
Here are short answers to questions I hear a lot.
- Do I need a PhD to work with AI? No. Practical machine learning requires curiosity, discipline, and domain knowledge more than a specific degree.
- How much data do I need? It depends. Start with a thousand labeled examples for simple problems. You will often need more for complex tasks like image recognition.
- Should I hire data scientists first? Hire someone to instrument data and build baselines. You can add senior data scientists as needs grow.
- Is AutoML a replacement for data scientists? It helps with prototyping. But you still need people who understand data quality, evaluation, and product integration.
Final thoughts — what really matters
Artificial intelligence basics and machine learning basics can feel intimidating. My advice is to focus on practical outcomes. What metric will improve? What data do you need? Can a simple model or rule get you half the gain? Start there.
Most successful AI projects I have seen follow a pattern: they start small, measure real impact, and then scale. They also respect the messy parts of engineering data. If you treat AI like a toolkit rather than a hammer, you will pick the right tool for the problem.
At vidyanova, we help teams translate business questions into practical AI experiments. If you want to walk through a project idea or need a quick review of your data strategy, I am happy to chat.
Helpful Links & Next Steps
Ready to take the next step? If you want a quick sanity check on an AI idea, or a short roadmap tailored to your business, Book a meeting and we will walk through it together.
FAQ
1. What is the main difference between artificial intelligence and machine learning?
Artificial intelligence is a broad concept where machines mimic human intelligence, while machine learning is a subset of AI that enables systems to learn from data and improve over time.
2. Is machine learning a part of artificial intelligence?
Yes, machine learning is a subset of artificial intelligence. AI includes many approaches, and machine learning is one of the most widely used methods within it.
3. Can artificial intelligence work without machine learning?
Yes, AI can work without machine learning using rule-based systems and predefined logic, but machine learning allows AI systems to adapt and become more accurate.
4. Which is better to learn first: artificial intelligence or machine learning?
Beginners usually start with machine learning basics because it is practical and easier to understand before moving on to broader AI concepts.
5. Where are artificial intelligence and machine learning used in real life?
AI and machine learning are used in voice assistants, recommendation systems, fraud detection, healthcare diagnostics, online learning platforms, and self-driving technology.